etcd业务压测
背景
- 目前业务使用到etcd集群,需对etcd集群基于业务层进行压测,以观察是否达到业务需求。
- 业务方想使用代理方式,可以通过本地proxy请求服务,把业务业务和etcd集群进行隔离。
机器角色
| IP | 用途 | 配置 |
|---|---|---|
| 10.202.18.173 | 压测客户端 | 云机器 16core/32g/200G SSD |
| 10.202.18.174 | 压测客户端 | 云机器 16core/32g/200G SSD |
| 10.202.18.175 | 压测客户端 | 云机器 16core/32g/200G SSD |
| 10.202.18.176 | etcd集群服务端[follower] | 物理机 40core/126g/800G SSD |
| 10.202.18.177 | etcd集群服务端[follower] | 物理机 40core/126g/800G SSD |
| 10.202.18.178 | etcd集群服务端[leader] | 物理机 40core/126g/800G SSD |
压测结果
| 序号 | 类型 | 并发namespace个数 | 并发数 | cpu使用率 | 流量 | 客户端是否超时 | 服务端是否超时 |
|---|---|---|---|---|---|---|---|
| 第一组 | 客户端 | 1 | 3000 | 25% | 600Mbits/s | 无 | |
| 第一组 | 服务端 | 1.42% | 600Mbits/s | 无 | |||
| 第二组 | 客户端 | 1 | 4000 | 20% | 1000Mbits/s | 有 | |
| 第二组 | 服务端 | 9% | 1460Mbits/s | 无 | |||
| 第三组 | 客户端 | 1 | 5000 | 20% | 1000Mbits/s | 有 | |
| 第三组 | 服务端 | 9% | 1400Mbits/s | 有 | |||
| 第四组 | 客户端 | 4 | 4000 | 16% | 600Mbits/s | 无 | |
| 第四组 | 服务端 | 9% | 600Mbits/s | 无 | |||
| 第五组 | 客户端 | 8 | 8000 | 16% | 600Mbits/s | 无 | |
| 第五组 | 服务端 | 9% | 600Mbits/s | 轻微可忽略 |
总结
- 一个
namespace下4000个进程并发时,云机器vpc出口流量已到上限1G,此时客户端出错报timeout,但etcd服务端无timeout日志,此时瓶颈为客户端,如下为该云机器vpc流量图: 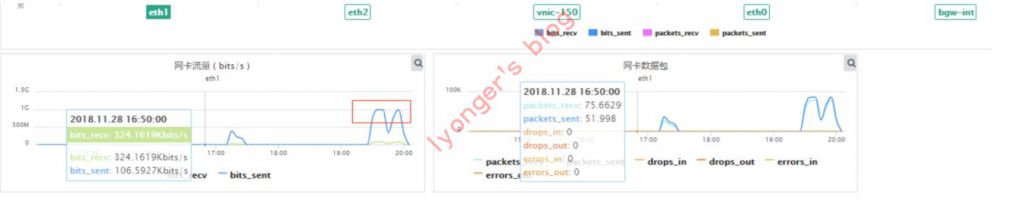
- 一个
namespace下5000个进程并发,etcd集群的物理机io出现延迟几十到数百毫秒,etcd服务端报timeout,此时已经到达该物理机配置下etcd集群的承载上线。此时客户端、服务端均出现瓶颈。 8个机器人,8个不同的namespace,每个机器人1000进程同时并发,etcd集群的cpu 10%不到,客户端、服务端日志均无timeout,可见不集中在一个namespace时,etcd集群还是挺强大的。
注意
etcd集群无namespace概念,是客户端模拟出来的。比如/dir/xxx即同一个dir目录下的请求为一个namespace。- 如果一个服下有数百万进程,建议业务启动时设置不同的
namespace,避免在同一个namespace下因进程太多而互相感知导致etcd集群出现瓶颈。
etcd-proxy调研
etcd提供了proxy功能,即代理功能,etcd可以代理的方式来运行。etcd代理可以运行在每一台主机,在这种代理模式下,etcd的作用就是一个反向代理,把客户端的etcd请求转发到真正的etcd集群。这种方式既加强了集群的弹性,又不会降低集群的写的性能。etcd proxy支持2种运行模式:readwrite和readonly,缺省的是readwrite,即proxy会将所有的读写请求都转发给etcd集群;readonly模式下,只转发读请求,写请求将会返回http 501错误。- 使用
proxy-etcd有如下优势:- 对业务环境隔离。
- 方便业务放配置,只需要连接通过本地连接。
- 方便扩缩容,对业务透明。
supervisor配置方式
1 | [program:etcd-proxy] |
使用方式
1 | #etcdctl --endpoint "http://127.0.0.1:22379" member list |
注意事项
proxy只支持API v2,不支持v3;- 尽管在
debug模式下,proxy本身的操作没日志记录。 - 在服务发现集群模式下,多启动的
etcd节点将会自动降级成读写模式的代理; - 代理不会自动变成
etcd集群节点,如要加入集群需要手工操作:etcd add命令将proxy节点加入集群、停止proxy进程或服务、删除proxy数据目录、使用正确的参数配置重新启动etcd进程或服务。
etcd集群数据备份
快照备份:
1 | #export ETCDCTL_API=3; /usr/local/bin/etcdctl --write-out="table" --endpoints='10.191.78.151:22380,10.191.78.152:22380,10.191.78.176:22380' snapshot save /home/project/var/tmp/etcd.backup |
集群镜像备份
- 此方法需要提前准备好新的镜像集群,假设为1.1.1.1:2389
1 | export ETCDCTL_API=3; /usr/local/bin/etcdctl make-mirror --endpoints='10.191.78.151:22380,10.191.78.152:22380,10.191.78.176:22380' 1.1.1.1:2389 |
etcd集群数据恢复
- etcd集群建议采用基数设备来搭建集群,可用性为
(N-1)/2,假设集群数量N是3台设备,可最多可故障1台设备,而不影响集群使用。
leader故障
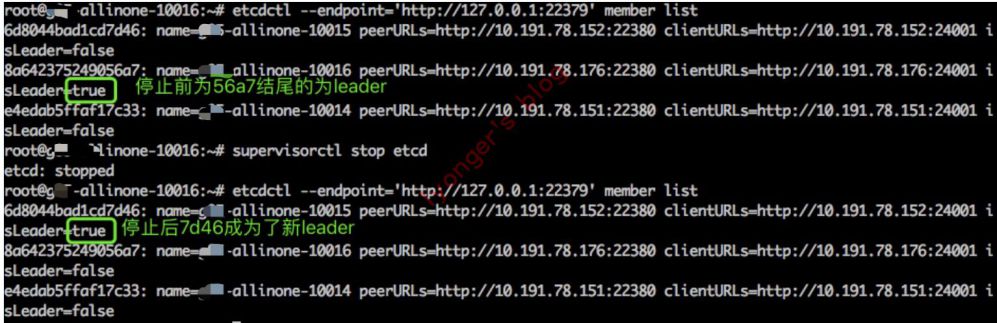
-
停掉leader节点以后,可以看到7d46结尾的节点被选择为leader。
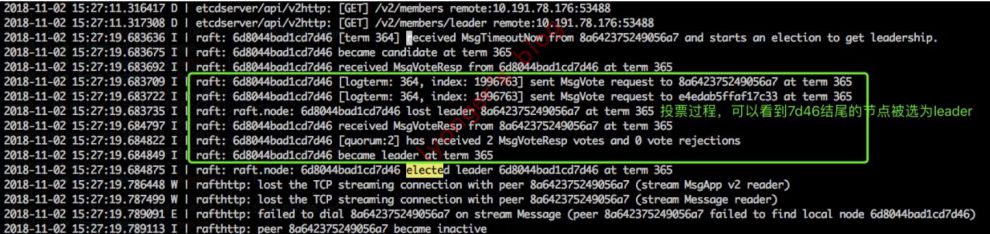
-
下面是7d46节点所在机器选举过程的日志。
-
说明3台节点down一台时,可以通过etcd-proxy继续读写,对业务是透明的。

-
但在leader选举期间,集群不能处理任何写入操作。在选举期间发送的写入请求排队等待处理,直到选出新的leader。已经发送给old leader但尚未提交的文字可能会丢失。新leader有权重写old leader的任何未提交的条目。从用户的角度来看,一些写入请求可能会超时,但是,没有提交的写入会丢失。
follower故障
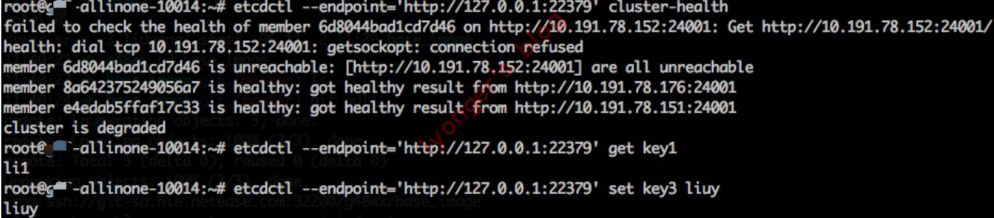
-
假设3台情况下,挂一台时,集群状态为degraded,但通过etcd-proxy仍可读写。
-
挂2台时,集群状态为
unavailable,可读不可写。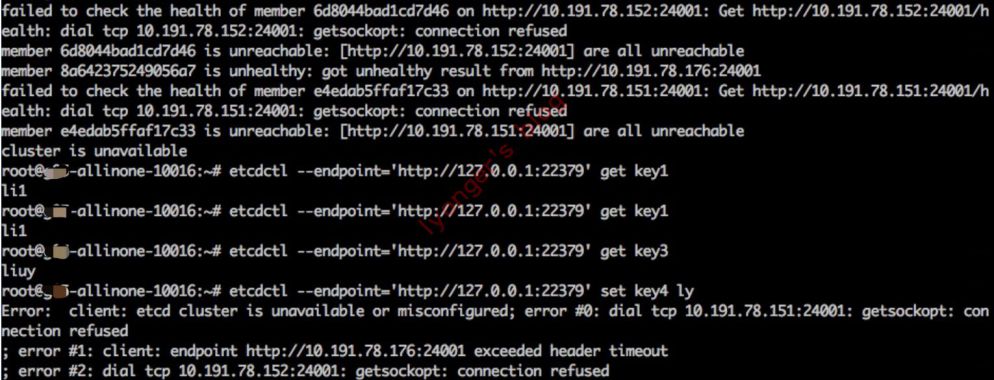
etcd性能优化
- 下面引入阿里巴巴技术专家
陈星宇的云原生技术公开课分享资料,觉得总结的很不错,就直接贴图了。
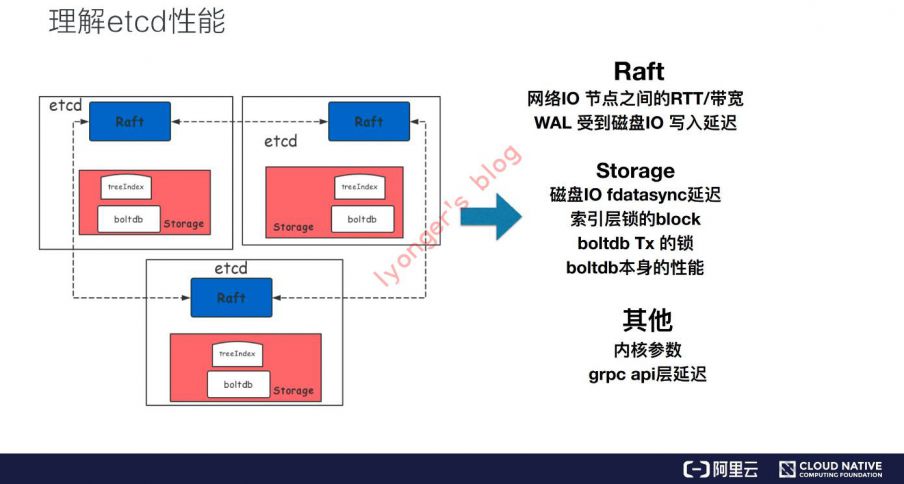
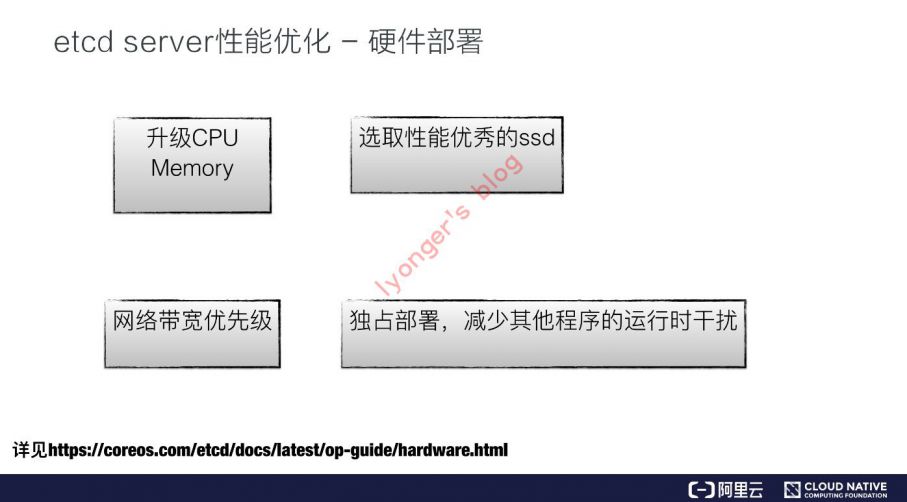

参考资料
-
Alibaba元原生技术公开课:https://edu.aliyun.com/course/1651
-
etcd-proxy官网文档:http://g.126.fm/01Q1M8U
赏
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
支付宝打赏
微信打赏
赞赏一下