记一次Gitlab Runner卡顿的详情分析
- 该问题排查耗时数周,下面分享一下整体的排查过程,仅供大家参考。
问题的背景
-
最近
Gitlab Runner服务偶尔接到用户反馈build超时和卡顿。下面是某个用户提供的问题截图。比如build超时: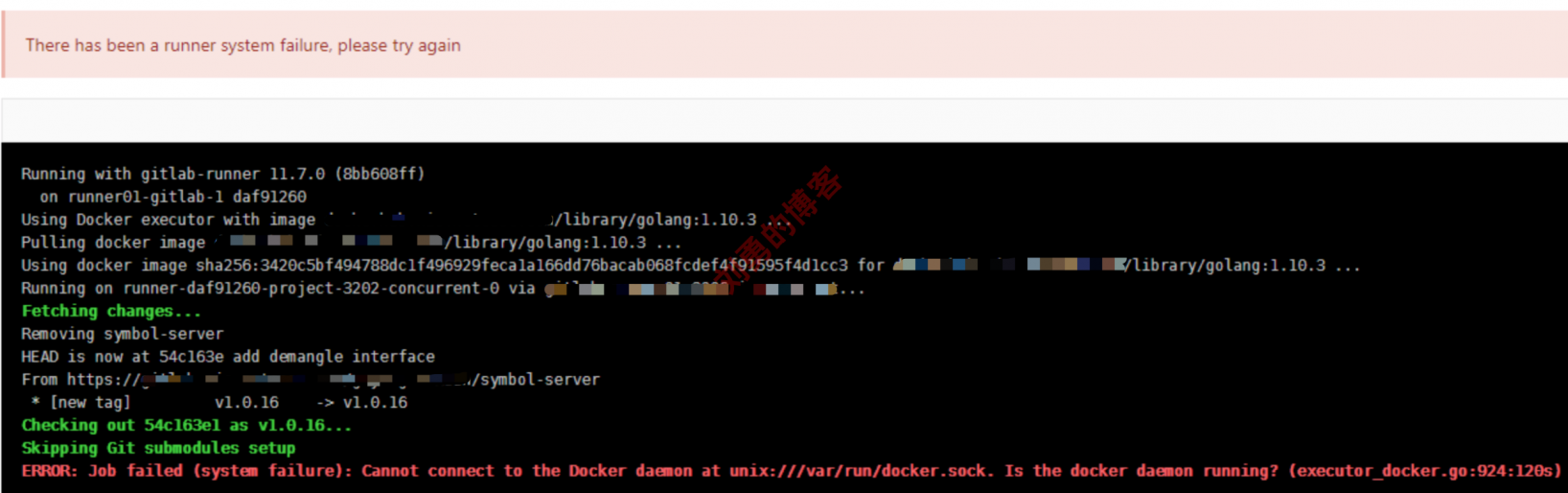
-
用户反馈卡顿,比如:

- 由于该问题具有普遍性,不同的用户在不同的
repo进行ci均会偶发性产生问题,于是着手做一次深入的排查。
故障机器的配置说明
- 机器为
KVM虚拟机,配置如下。
1 | 系统版本:Debian9.7 |
故障的分析详情
第一次排查
-
在初次遇到这个问题结合用户反馈的截图,怀疑看
docker.sock不响应。所以,当时尝试在事故发生现场,努力的strace追踪docker.sock的系统调用情况,下面是某次现场分析的截图,发现请求socket确实会有卡住的现象。然而这一次过了以后,没有深入找到原因,因为现场没有保存。下面是故障时的strace截图。
第二次排查
- 接着某天再此收到用户报障,这次又深入了一点,找到了系统层的
CPU异常,且IO使用率高。在这里看到cpu的st占用高,就怀疑是虚拟机的资源复用太严重,所以就让同事把这台机器迁移到了独占宿主机,目的是排除CPU的影响。其实这里忽略了io高的原因,当时被st高的现象给迷惑了。-
系统
top分析截图

-
io监控图数据

-
第三次排查
- 迁移了宿主以后,发现没过几天又接到用户的报障。由于已经排除了
CPU的影响。思路就集中在了其他资源上,这次定位发现系统io存在可疑,如下图:-
系统整体使用情况

-
iotop定位到loop内核线程io高,其实内核线程的祖先是pid为2的kthreadd进程。

-
loop内核线程确实有读发生,且在进程分布中读的量最大。

-
- 到了第三次排查,大概定位到了瓶颈为
loop内核线程,但是loop内核线程到底在做什么事情呢,这个问题值得思考,读到这里,您会有哪些思考呢?其实要知道内核线程具体的内部调用栈情况,需要使用到动态追踪工具,那业界优秀的动态追踪工具有哪些呢?下文就为你揭晓答案。
第四次排查
- 这一次排查使用
perf工具保存了现场,并利用perf保存的数据生成了火焰图,定位到热点函数是loop_queue_work,其对应的内核源码定义如下

- 从
perf火焰图可知,热点函数是loop_queue_work。这里普及一下火焰图的查看技巧,火焰图一般是从下往上看,横轴表示采样数和采样比例,一个函数占用的横轴越宽就代表它的执行时间越长。纵轴表示调用栈,上下相邻的2个函数中,下面的函数是上面函数的父函数。

- 从热点函数名中可知,含有队列(queue)2个字,于是想到了磁盘调度算法,接着尝试调整虚拟机的磁盘调度算法。发现虚拟机使用了
Ceph RBD磁盘,不支持修改磁盘调度算法。于是这里卡住了继续下一步的线索。

第五次排查
-
在这一次排查中,终于拨开了迷雾。在一次偶然的机会,有一个用户提供了一个和前几次不一样的报错截图,如下图:

-
排查到
gitlab runner机器上的devmapper存储驱动目录确实挺大,但是为啥镜像清理了以后,空间依旧没释放呢。于是网上查了一番,发现这个存储驱动已经不推荐使用了,有性能问题。关于Docker如何选择存储驱动,请参考这里。

-
至于我们这里为什么有使用
devmapper这个驱动,是因为在一次升级系统内核时做的变更导致。我们查看到线上docker运行到存储驱动正是devmapper。

-
这一次机智的用
perf保存了现场,再次分析热点函数,看到和xfs文件系统相关。

-
在2个月前升级系统内核时,由于在xfs文件系统下没有打开下面这个选项(
ftype=1才代表打开)导致只能使用devmapper驱动。从这里再联想到热点函数也是显示xfs文件系统相关,不得不考虑是存储驱动导致的性能问题了。

- 在没有打开这个选项(ftype=1)的情况下使用overlay存储驱动会报错如下:
1 | could not use snapshotter overlayfs in metadata plugin" error="/home/gitlab/var/lib/docker/containerd/daemon/io.containerd.snapshotter.v1.overlayfs does not support d_type. If the backing filesystem is xfs, please reformat with ftype=1 to enable d_type support |
-
而
Docker有在源码里面也有定义使用的存储驱动优先级。

-
于是备份数据后使用
mkfs.xfs -n ftype=1 /dev/vdc1命令重新格式化磁盘,打开ftype选项。接着强制配置Docker进程使用overlay2的存储驱动,再次模拟用户触发ci任务,观察发现loop内核线程不会有io产生。整个系统的io也降低了。再更改回devmapper以后,loop内核线程又变高了,由此定位到了最终问题。
自测结果
- 下面是使用同一个
repo,在同一个gitlab站点测试使用devmapper和overlay2不同存储驱动的表现情况。-
使用
overlay2存储驱动的io数据
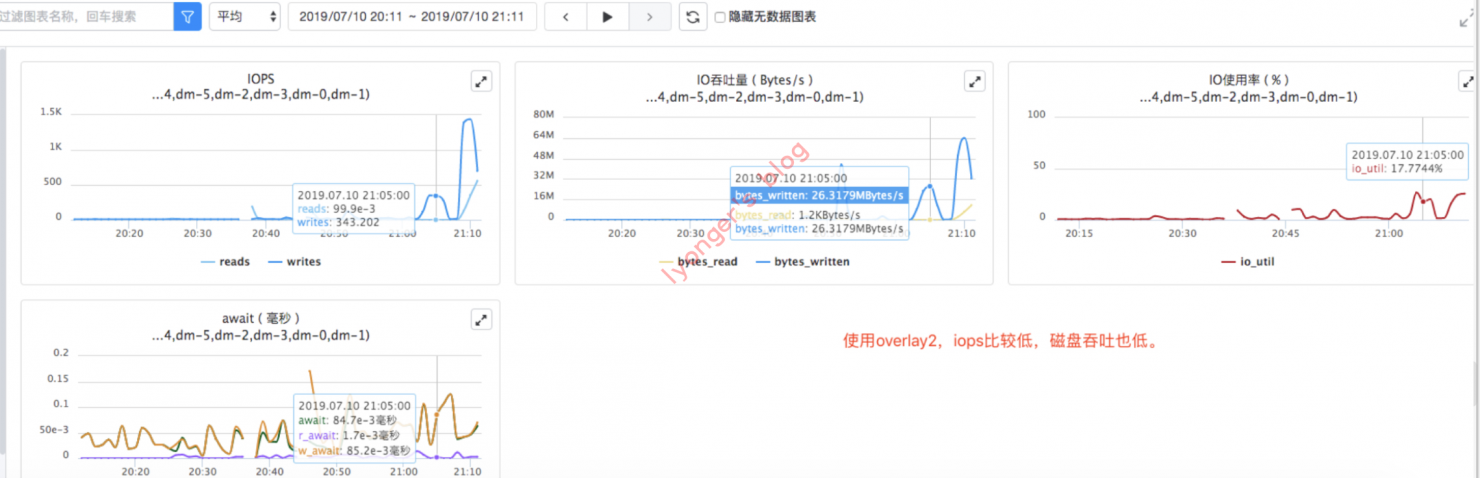
-
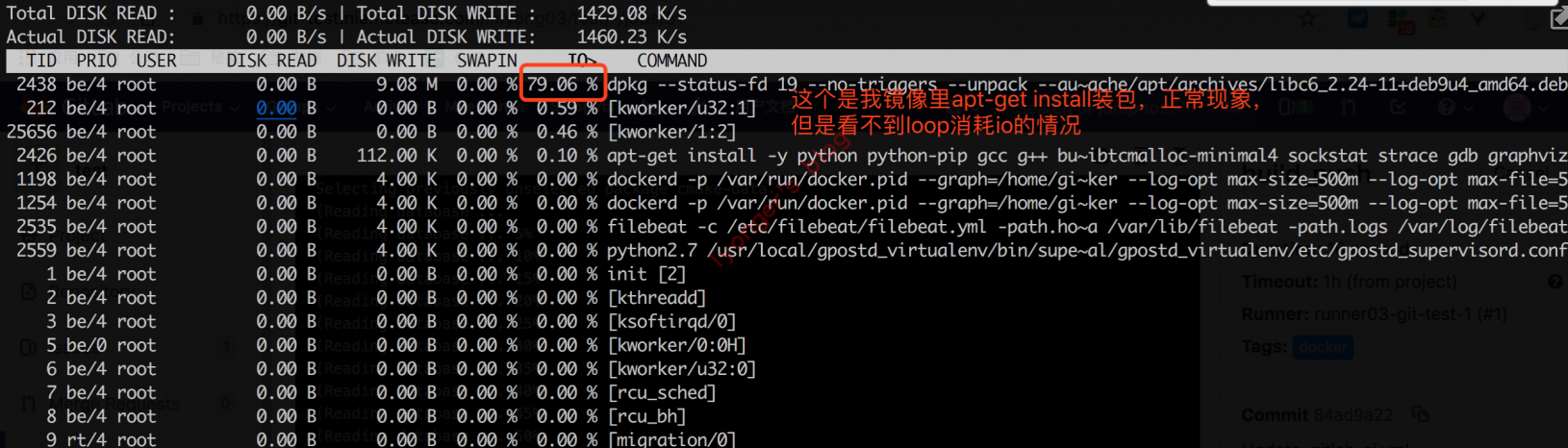
使用
iotop看不到loop内核线程有io情况,更不会排在首位。
-
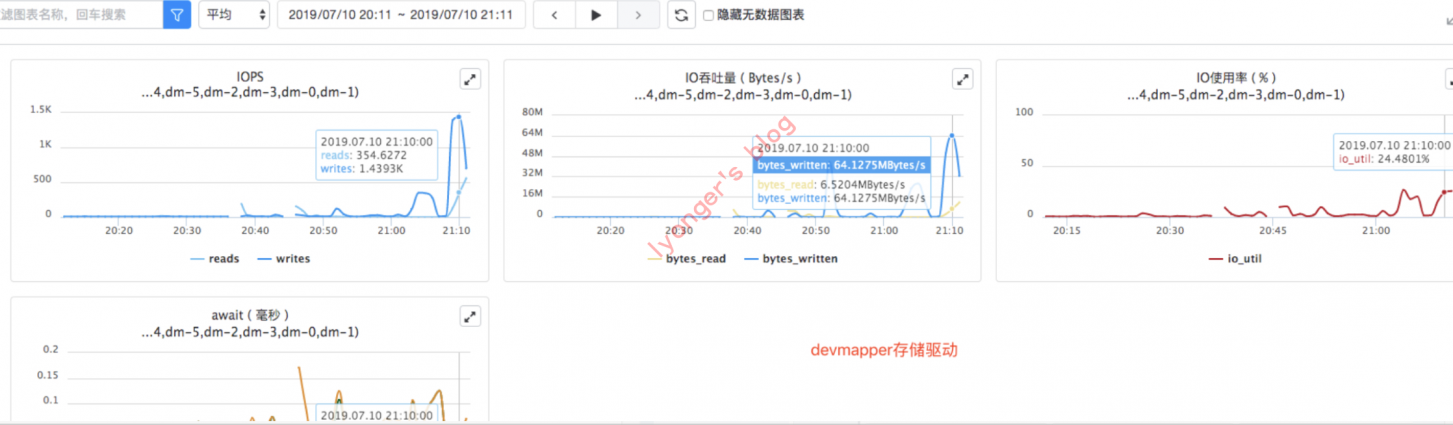
使用
devmapper存储驱动的io数据
-
使用
iotop查看到loop内核线程io消耗且排在了首位。

-
思路总结
- 从这一次的故障诊断分析来看,耗时较久,从一开始的现象到最终的分析,都是逐步进行的。故障发生的时刻往往短暂,所以想办法保存现场数据或者复现故障显得尤为重要。对于性能优化,基本是长期跟踪,动态调整,大部分的分析是从系统到进程或者线程,再到内核热点函数,再到操作系统原理。 最后期待本文能对你以后的故障排查提供帮助,知识在于分享,更希望你可以把此文分享给你的朋友。
资料参考
- 优秀的动态追踪工具参考:https://zhuanlan.zhihu.com/p/24124082
- 火焰图使用参考:https://github.com/brendangregg/FlameGraph
- perf工具使用参考:http://www.brendangregg.com/perf.html
推荐阅读
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
赞赏一下